



















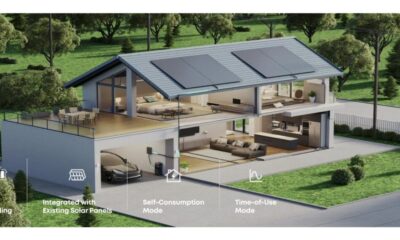
The growing demand for clean and reliable energy has made solar-powered solutions more popular than ever. A power station combined with a solar power generator offers...

La television change. Etes-vous pret ? Un soir ordinaire en France. Dans un appartement parisien, un pere regarde la Ligue 1 en direct sur son televiseur...

Your roof protects everything beneath it. In Utah County, that protection must withstand snow, ice, wind, and intense summer heat. Homes in Orem face heavy seasonal...

Tokyo, Japan — In 2026, modern finance is overwhelmed by the complexity of readily accessible information, market volatility, and algorithmically generated content. Flashy dashboards, multi-asset scatterplots,...
Milnerton is a community of incredible views, from the iconic sights of Table Mountain across the bay to the bustling activity of the Century City precinct....

Nestled at the base of the Constantiaberg mountains, Tokai is a vibrant hub where the forest meets a bustling commercial and residential community. From the active...
The gaming industry has grown far beyond its early days of pixelated screens and simple mechanics. In 2025, gaming stands as one of the most influential...
Introduction: A New Chapter in Fashion Innovation The fashion industry is undergoing a major transformation, driven by the growing demand for personalization and sustainability. Print-on-demand (POD)...
In 2025, the aesthetic treatment industry is undergoing a profound transformation. Driven by technological innovation, shifting consumer values, and a growing emphasis on holistic wellness, treatments...







































